A real audit of a fake store.
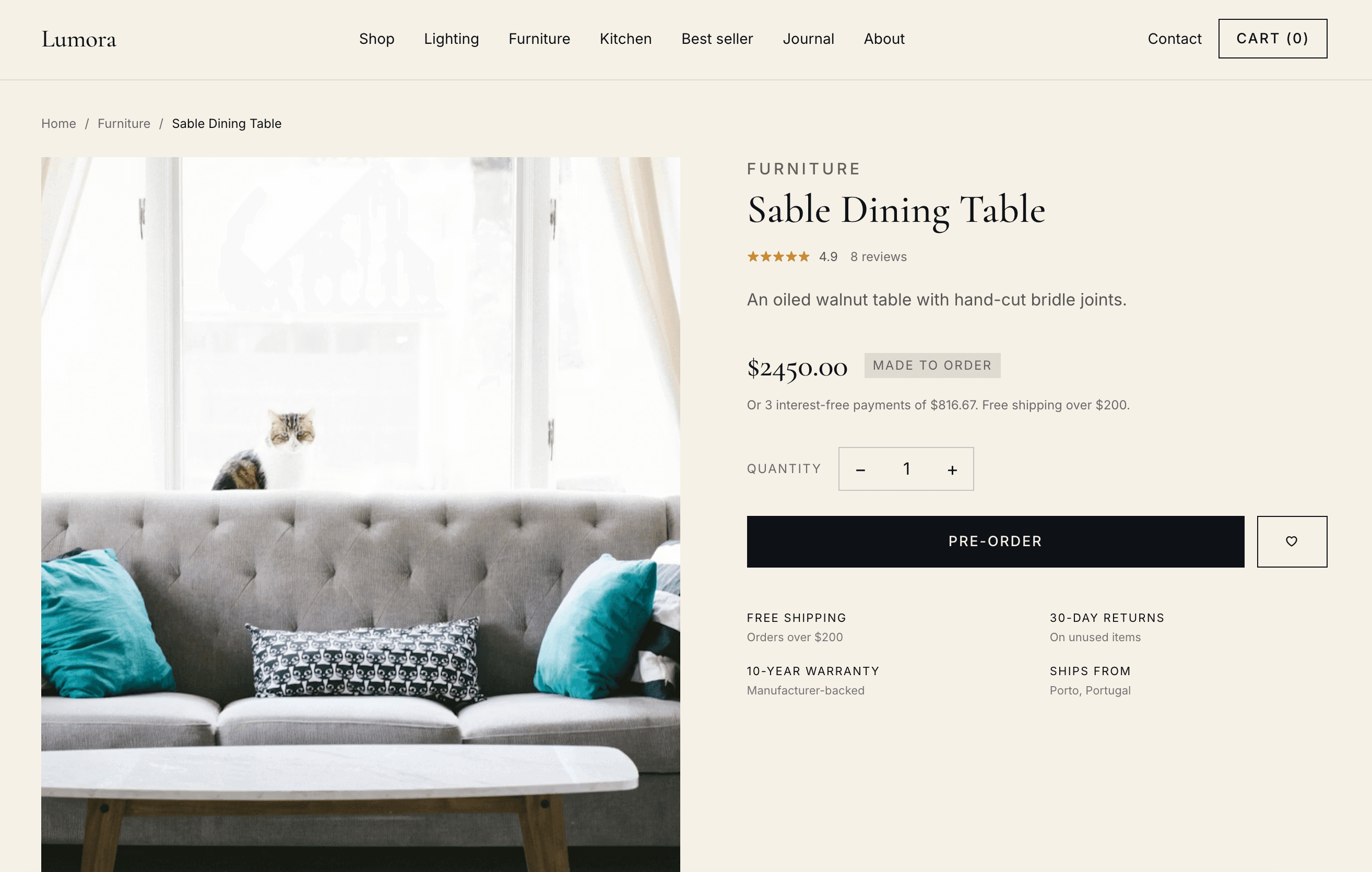
The test site is a fully built Next.js e-commerce store called Lumora. It has a homepage, 18 products across 5 categories, a blog, a search page, and a cart. Designed to look completely normal at first glance — and to break under careful auditing.
Lumora — a home goods store.
Sells (fictional) lighting, furniture, kitchen, decor, and outdoor goods. Built in Next.js 15 with the App Router, fully SSR — every surface you'd expect from a production e-commerce build, configured the way a real engineering team would configure it.
Your job: audit it. Find what's wrong. Send us your list. We don't tell you where to look — that's the test.
- Stack
- Next.js 15, App Router, SSR
- Pages
- 29 routes, 18 product pages
- Issues planted
- 60+
- Tiers
- Apprentice → Guru
- Time to audit
- 1–8 hours
- Tools allowed
- Browser + dev tools only
Looks normal. Behaves normally. Audits badly.
Every layer is built the way a real engineering team would build it. The faults are hidden inside that production-feeling surface — that's the whole point of the test.
The mindset that scores.
A page is rendered, then served, then crawled, then validated. Each of those is a separate surface that can drift from the others. The strongest auditors check all of them.
What looks correct in a browser may not be what gets indexed. View source, response headers, and structured data validators all tell different stories.
If you find the same problem on every product page, that's one finding, not eighteen. Identify the pattern and describe it once.
Generic statements don't get credit. Each finding needs a specific page or surface and a specific thing that's wrong with it. The grader is conservative — vague claims map to nothing.
A few small rules.
- 01Browser and dev tools only.
Inspect, View Source, Network panel, Console — yes. External crawlers, audit suites, AI agents, scripts — no. The test site enforces this at the network level by blocking known bot user-agents and the IP ranges of major audit tools.
- 02No piping the test site through AI.
Don't paste a page into ChatGPT and ask for issues. The test measures your auditing, not the model's. We can detect the obvious patterns of AI-generated submissions and the grader devalues them.
- 03One finding, one line.
Each issue you submit needs a sentence describing what's wrong and where you found it. Pasted screenshots are welcome but not required.
- 04Duplicate findings count once.
If the same problem manifests across many pages, list it once. Patterns count, not page-counts.
- 05Inferred causes don't earn extra points.
If you find the symptom, you get the credit. Diagnosing the underlying framework misconfiguration is satisfying but not scored.
- 06Generic statements get null.
The grader is conservative on purpose. 'The site has problems' or 'metadata could be better' don't match anything on the answer key.
Take the brief. Take the test.
Sign up, get the test-site URL, audit at your pace, submit when you're done.